



NVIDIA's newest GeForce RTX 5090 sees inference performance on the DeepSeek R1 much faster than AMD's RX 7900 XTX, credited to the new fifth-generation Tensor Cores.
Accessing DeepSeek's Reasoning Models With NVIDIA's New RTX GPUs Is Now Pretty Easy, That Too With High-Class Performance
Well, it seems like consumer GPUs might be one of the best ways to run high-end LLM models on local machines, as both NVIDIA and AMD are determined to provide suitable environments for this execution. We recently saw AMD showcasing the prowess of the RDNA 3 flagship GPU on the DeepSeek R1 LLM model, and now, Team Green has responded by showcasing inference benchmarks running on their newest RTX Blackwell GPUs, and the numbers indeed show that the GeForce RTX 5090 has dominated.
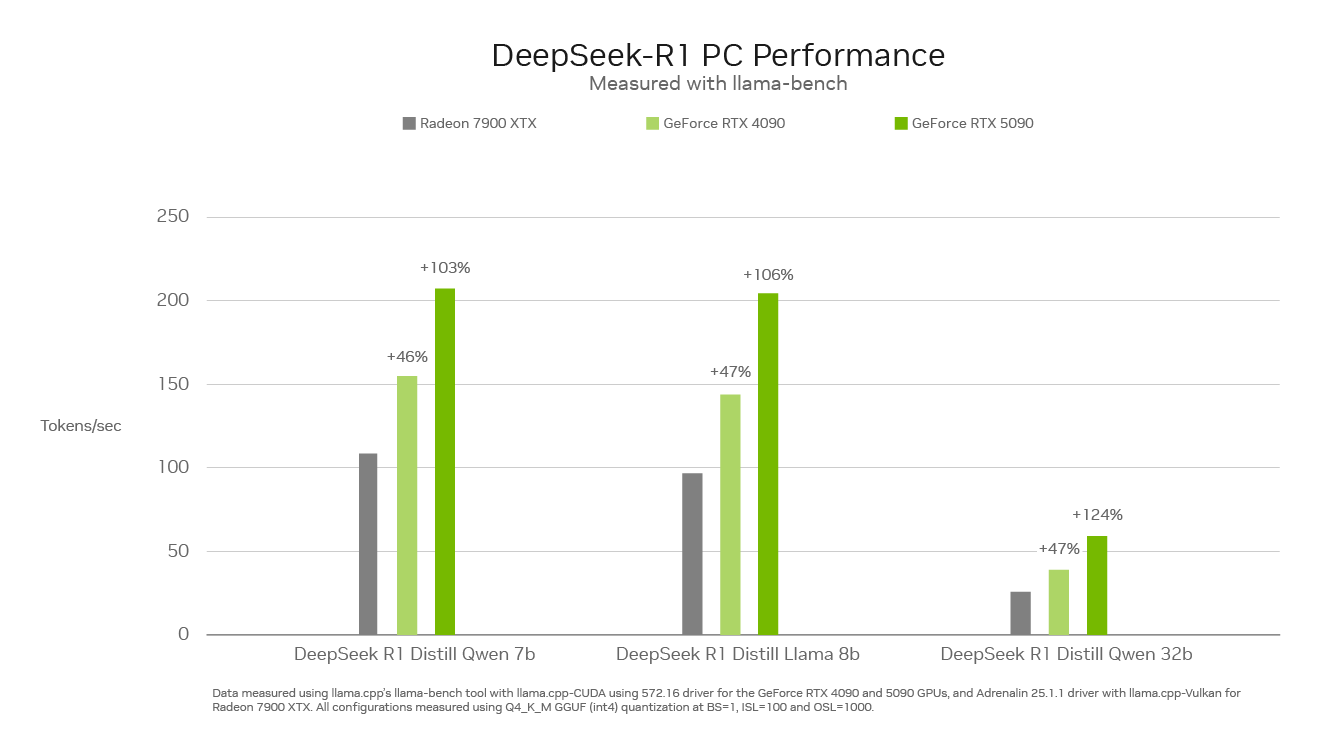
Across multiple DeepSeek R1 models, the GeForce RTX 5090 shows a clear lead from the Radeon RX 7900 XTX and even the previous-gen counterpart. The GPU has managed to run up to 200 tokens per second in Distill Qwen 7b and Distill Llama 8b, which marks almost two times more than what AMD's RX 7900 XTX achieved. This shows how dominant AI performance on NVIDIA's GPUs is going to be, and with the extensive "RTX on AI" support, we are going to see edge AI on consumer PCs are lot more frequently.
For those eager to run DeepSeek R1 on NVIDIA's RTX GPUs, the firm has published a dedicated blog to guide users, and interestingly, it is as simple as running any chatbot over the internet. Here's how you can access it:


To help developers securely experiment with these capabilities and build their own specialized agents, the 671-billion-parameter DeepSeek-R1 model is now available as an NVIDIA NIM microservice preview on build.nvidia.com. The DeepSeek-R1 NIM microservice can deliver up to 3,872 tokens per second on a single NVIDIA HGX H200 system.
Developers can test and experiment with the application programming interface (API), which is expected to be available soon as a downloadable NIM microservice, part of the NVIDIA AI Enterprise software platform.
The DeepSeek-R1 NIM microservice simplifies deployments with support for industry-standard APIs. Enterprises can maximize security and data privacy by running the NIM microservice on their preferred accelerated computing infrastructure.
- NVIDIA
With NVIDIA's NIM, developers and enthusiasts can easily try out the AI model on their local builds, and this indeed means that not only will your data be safeguarded, but running locally can also provide improved performance, given that the hardware capabilities support it.

About the author: Muhammad Zuhair is a hardware and technology reporter for Wccftech, specializing in the semiconductor industry and the complex interplay between technology, manufacturing, and geopolitics. His coverage focuses on the corporate strategies and technological roadmaps of industry giants like TSMC, NVIDIA, Samsung, and Intel. Zuhair's expertise lies in deconstructing complex topics such as fabrication nodes (e.g., 2nm process), the economic impact of policies like the CHIPS Act, and the strategic development of AI infrastructure from NVIDIA, AMD and Intel.
Follow Wccftech on Google to get more of our news coverage in your feeds.



