
AMD has unveiled its first small language model, AMD-135M, which utilizes speculative decoding to leverage AI capabilities, ultimately leading to an enhanced technology process.
AMD Decides To Jump Into The AI Model Bandwagon, Reveals a Small Large Language Model That Is More Efficient at Token Generation
[Press Release]: In the ever-evolving landscape of artificial intelligence, large language models (LLMs) like GPT-4 and Llama have garnered significant attention for their impressive capabilities in natural language processing and generation.
However, small language models (SLMs) are emerging as an essential counterpart in the AI model community offering a unique advantage for specific use cases. AMD is excited to release its very first small language model, AMD-135M with Speculative Decoding. This work demonstrates the commitment to an open approach to AI which will lead to more inclusive, ethical, and innovative technological progress, helping ensure that its benefits are more widely shared, and its challenges more collaboratively addressed.
AMD-135M: First AMD Small Language Model
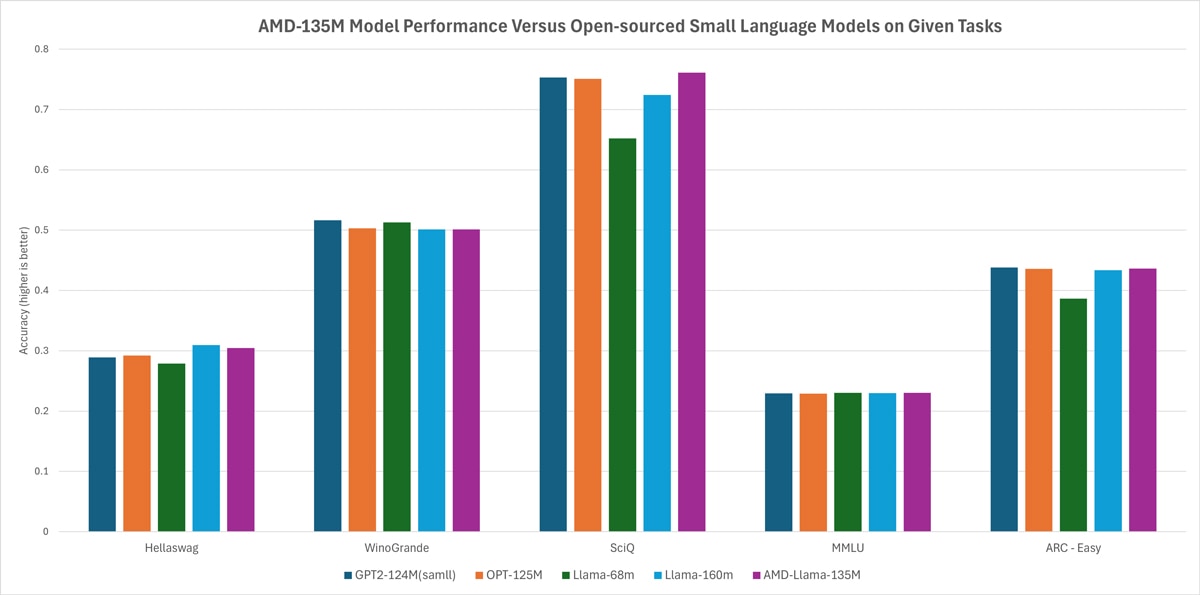
AMD-135M is the first small language model for Llama family that was trained from scratch on AMD Instinct™ MI250 accelerators utilizing 670B tokens and divided into two models: AMD-Llama-135M and AMD-Llama-135M-code.
- Pretraining: The AMD-Llama-135M model was trained from scratch with 670 billion tokens of general data over six days using four MI250 nodes.
- Code Finetuning: The AMD-Llama-135M-code variant was fine-tuned with an additional 20 billion tokens of code data, taking four days on the same hardware.
The training code, dataset, and weights for this model are open-sourced so that developers can reproduce the model and help train other SLMs and LLMs.
Optimization with Speculative Decoding
Large language models typically use an autoregressive approach for inference. However, a major limitation of this approach is that each forward pass can only generate a single token, resulting in low memory access efficiency and affecting overall inference speed.
The advent of speculative decoding has solved this problem. The basic principle involves using a small draft model to generate a set of candidate tokens, which are then verified by the larger target model. This approach allows each forward pass to generate multiple tokens without compromising performance, thereby significantly reducing memory access consumption, and enabling several orders of magnitude speed improvements.
Inference Performance Acceleration
Using AMD-Llama-135M-code as a draft model for CodeLlama-7b, we tested the inference performance with and without speculative decoding on the MI250 accelerator for data center, and Ryzen™ AI processor (with NPU) for AI PC. For the particular configurations that we tested using AMD-Llama-135M-code as the draft model, we saw a speedup on the Instinct MI250 accelerator, Ryzen AI CPU[2], and on Ryzen AI NPU[2] versus the inference without speculative decoding.[3] The AMD-135M SLM establishes an end-to-end workflow, encompassing both training and inferencing, on select AMD platforms.

About the author: Muhammad Zuhair is a hardware and technology reporter for Wccftech, specializing in the semiconductor industry and the complex interplay between technology, manufacturing, and geopolitics. His coverage focuses on the corporate strategies and technological roadmaps of industry giants like TSMC, NVIDIA, Samsung, and Intel. Zuhair's expertise lies in deconstructing complex topics such as fabrication nodes (e.g., 2nm process), the economic impact of policies like the CHIPS Act, and the strategic development of AI infrastructure from NVIDIA, AMD and Intel.
Follow Wccftech on Google to get more of our news coverage in your feeds.



