


Google's newest open-source model, the Gemma 4, can now be deployed on NVIDIA's consumer-grade hardware, offering optimal performance for agentic AI workloads.
NVIDIA Takes Open-Source Deployment With RTX GPUs to New Levels, With Google's Gemma 4
[Press Release]: Open models are driving a new wave of on-device AI, extending innovation beyond the cloud to everyday devices. As these models advance, their value increasingly depends on access to local, real-time context that can turn meaningful insights into action. Designed for this shift, Google’s latest additions to the Gemma 4 family introduce a class of small, fast and omni-capable models built for efficient local execution across a wide range of devices.
Google and NVIDIA have collaborated to optimize Gemma 4 for NVIDIA GPUs, enabling efficient performance across a range of systems — from data center deployments to NVIDIA RTX-powered PCs and workstations, the NVIDIA DGX Spark personal AI supercomputer and NVIDIA Jetson Orin Nano edge AI modules.
Gemma 4: Compact Models Optimized for NVIDIA GPUs
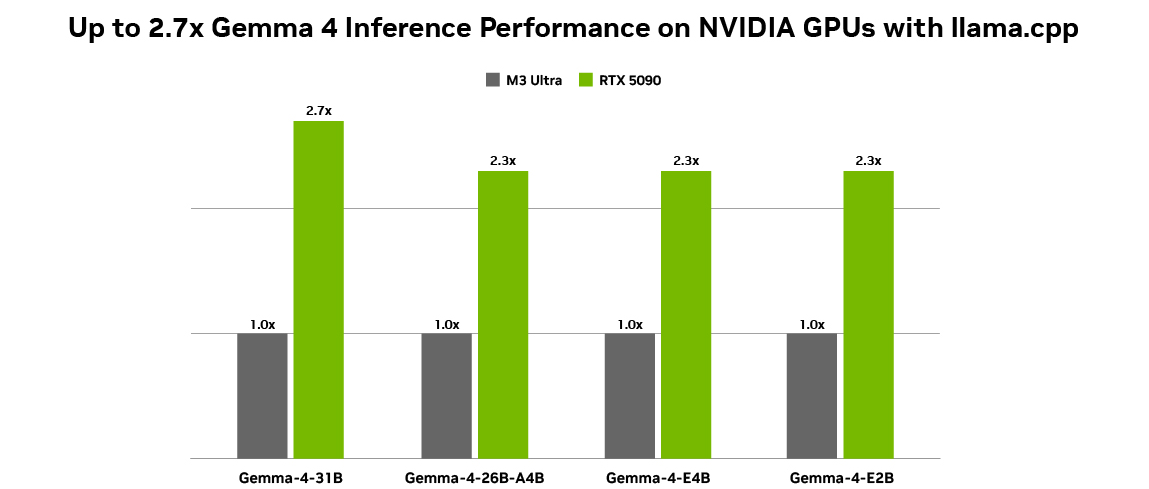
The latest additions to the Gemma 4 family of open models— spanning E2B, E4B, 26B, and 31B variants — are designed for efficient deployment from edge devices to high-performance GPUs.

This new generation of compact models supports a range of tasks, including:
- Reasoning: Strong performance on complex problem-solving tasks.
- Coding: Code generation and debugging for developer workflows.
- Agents: Native support for structured tool use (function calling).
- Vision, Video, and Audio Capabilities: Enables rich multimodal interactions for object recognition, automated speech recognition, and document or video intelligence.
- Interleaved Multimodal Input: Mix text and images in any order within a single prompt.
- Multilingual: Out-of-the-box support for 35+ languages, pretrained on 140+ languages.
The E2B and E4B models are built for ultra-efficient, low-latency inference at the edge, running completely offline with near-zero latency across many devices, including Jetson Nano modules.
The 26B and 31B models are designed for high-performance reasoning and developer-centric workflows, making them well-suited for agentic AI. Optimized to deliver state-of-the-art, accessible reasoning, these models run efficiently on NVIDIA RTX GPUs and DGX Spark — powering development environments, coding assistants, and agent-driven workflows.
As local agentic AI continues to gain momentum, applications like OpenClaw are enabling always-on AI assistants on RTX PCs, workstations, and DGX Spark. The latest Gemma 4 models are compatible with OpenClaw, allowing users to build capable local agents that draw context from personal files, applications, and workflows to automate tasks.
Getting Started: Gemma 4 on RTX GPUs and DGX Spark
NVIDIA has collaborated with Ollama and llama.cpp to provide the best local deployment experience for each of the Gemma 4 models.
To use Gemma 4 locally, users can download Ollama to run Gemma 4 models or install llama.cpp and pair it with the Gemma 4 GGUF Hugging Face checkpoint. Additionally, Unsloth provides day-one support with optimized and quantized models for efficient local fine-tuning and deployment via Unsloth Studio. Start running and fine-tuning Gemma 4 in Unsloth Studio today.
Running open models like the Gemma 4 family on NVIDIA GPUs achieves optimal performance because NVIDIA Tensor Cores accelerate AI inference workloads to deliver higher throughput and lower latency for local execution .Plus, the CUDA software stack ensures broad compatibility across leading frameworks and tools, enabling new models to run efficiently from day one
This combination allows open models like Gemma 4 to scale across a wide range of systems — from Jetson Orin Nano at the edge to RTX PCs, workstations and DGX Spark — without requiring extensive optimization.


About the author: Muhammad Zuhair is a hardware and technology reporter for Wccftech, specializing in the semiconductor industry and the complex interplay between technology, manufacturing, and geopolitics. His coverage focuses on the corporate strategies and technological roadmaps of industry giants like TSMC, NVIDIA, Samsung, and Intel. Zuhair's expertise lies in deconstructing complex topics such as fabrication nodes (e.g., 2nm process), the economic impact of policies like the CHIPS Act, and the strategic development of AI infrastructure from NVIDIA, AMD and Intel.
Follow Wccftech on Google to get more of our news coverage in your feeds.





{kind=link}